在计算机算力大幅提升的背景下,计算机视觉领域在近几年发展非常迅速,目标检测、跟踪和识别相关算法的精度和速度也得到了巨大的提升,并应用在了很多领域。YOLO系列算法作为One Stage目标检测算法的开山之作,从发布之日起就吸引了众多计算机视觉工作者的关注,而YOLOv3作为原作者Redmon关于YOLO系算法的最后一版,如今也被用于视觉检测的众多领域。
YOLOv3发布于2018年4月,是YOLO系列算法的第三个版本,主要内容则是在YOLOv1和v2的基础上做进一步的改进,提升其物体检测的速度和精度,同时也优化了对小物体的检测性能。其主要改进之处在于:
1.调整了网络结构,使用Darknet-53作为backbone网络。
2.使用多尺度特征进行对象检测,优化了对小物体的检测效果。
3.分类用logistics取代了softmax,方便支持多标签物体。
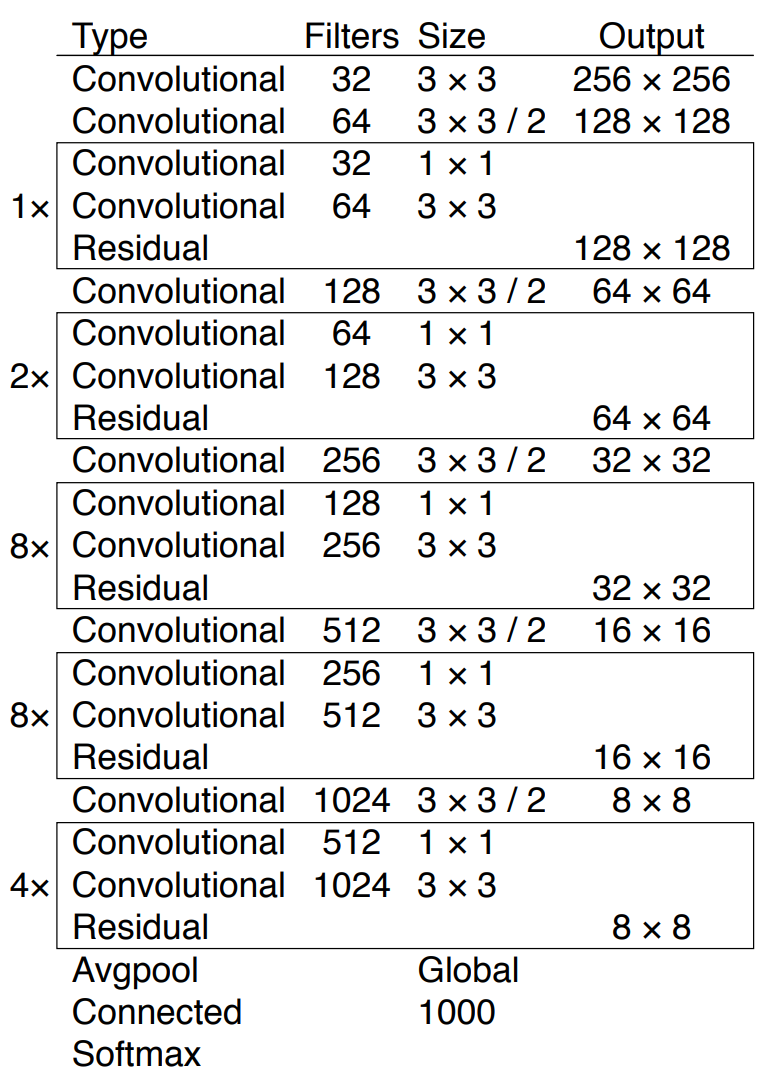
YOLOv3的backbone网络使用了darknet-53(53个卷积层),用于图像基本特征提取,相比于YOLOv2的darknet-19加深了网络层数。同时,Darknet-53引入了残差网络Resnet的做法,在一些层之间设置了快捷链路(shortcut connections)操作。图中每一个框表示一个残差组件,左边相乘的数字为残差组件的个数。
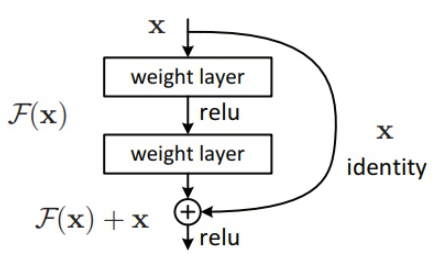
下图则为残差组件的示意图,每个残差组件有两个卷积层和一个快捷链路。
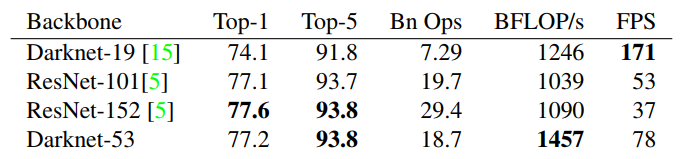
作者在原文中也将darknet-53与其他backbone网络进行了对比,从下图中可以看出,darknet-53每秒能处理78张图,相比于darknet-19要慢很多,但是仍然快于相似精度的ResNet检测速度,因此YOLOv3依然保持了高性能。
早在YOLOv1中作者就借鉴了RCNN中的候选框(anchor)提出了bounding box的概念,并使用边框回归来预测物体的位置坐标。通过事先规定每张图像中bounding box的数量,给定一个大致的物体候选区域,确定候选框中存在物体后对边框进行微调,使其更接近真实的bounding box,这个过程就是边框回归。YOLO算法是用回归做物体检测的先驱。
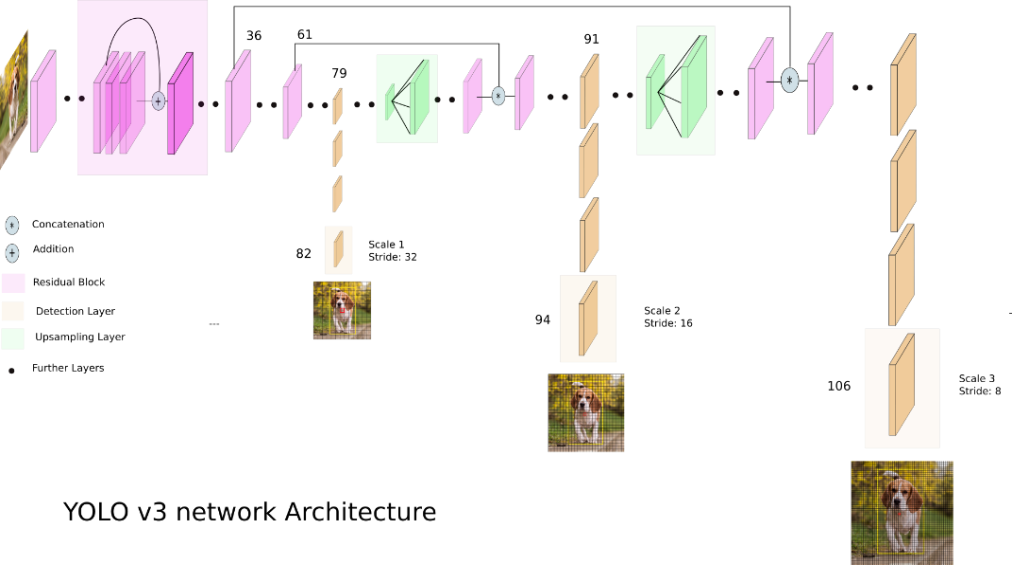
在YOLOv1中,网络是直接回归检测框的宽和高,这种方式对于小尺寸物体检测效果有限,因此在YOLOv2中改为了回归基于先验框的变化值,降低了网络的学习难度,整体精度提升不小。而在YOLOv3中,作者更是借鉴了金字塔特征图的思想来对不同尺寸的物体进行检测。下图为YOLOv3的网络结构示意图。
图中的Stride为下采样步长,可理解为下采样倍数。如82层中,Stride为32,则下采样倍数为32倍,假如输入图像为416*416,则下采样后为13*13。同理,94层和106层经过下采样后则变成24*24和48*48。可以看出,下采样倍数越高,特征图的感受也越大,能检测到的更大的物体;反之则感受野越小,可用于检测小尺寸物体。这对应了金字塔特征图的思想,即小尺寸特征图用于检测大尺寸物体,大尺寸特征图检测小尺寸物体。
下采样是针对输入图像而言,而在实际的网络结构中,还用到了上采样。可以看到在79层得到13*13的下采样特征图后,又在之后对其进行了上采样操作,得到了24*24的特征图,然后与61层的特征图融合(concatenation),从而得到了第91层的特征图,并经过几个卷积层后得到了94层的16倍下采样特征图。同理,在91层之后经过上采样、融合和卷积操作后得到了106层的8倍下采样特征图。
为了匹配输出特征图数量和尺寸的变化,先验框(bounding box)的尺寸和数量也进行了重新设计。在YOLOv2中,作者使用了k-means聚类得到不同尺寸的先验框,这个作法也延续到了YOLOv3中。在上面三种不同尺寸的输出特征图中,每一种聚类出三个不同尺寸的先验框,总共聚类出9个。作者在COCO数据集中聚类出的9个先验框尺寸分别为:(10x13),(16x30),(33x23),(30x61),(62x45),(59x119),(116x90),(156x198),(373x326)。
分配上,在最小的13*13特征图上(有最大的感受野)应用较大的先验框(116x90),(156x198),(373x326),适合检测较大的对象。中等的26*26特征图上(中等感受野)应用中等的先验框(30x61),(62x45),(59x119),适合检测中等大小的对象。较大的52*52特征图上(较小的感受野)应用较小的先验框(10x13),(16x30),(33x23),适合检测较小的对象。
YOLOv3在预测物体类别时的激活函数由softmax改成了logistic。原因在于作者对比了两者的预测性能,发现使用logistic时效果比softmax好,此外,修改后的激活函数能适用待检测数据集中物体有多个标签的情况,如一个人同时有woman和person两个标签。
YOLOv3借鉴了残差网络结构,形成更深的网络层次,结合多尺度特征图检测,进一步提升了mAP得分及小物体检测效果。如下图所示,当使用COCO mAP50作为评估指标时,YOLOv3的表现非常惊人,在精确度相当的情况下,YOLOv3的速度是其他模型的3,4倍。
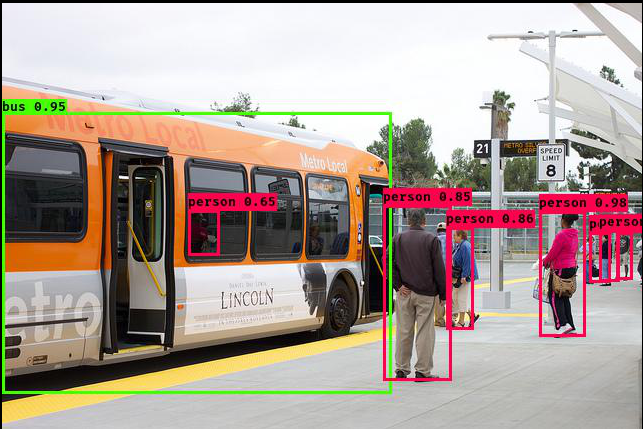
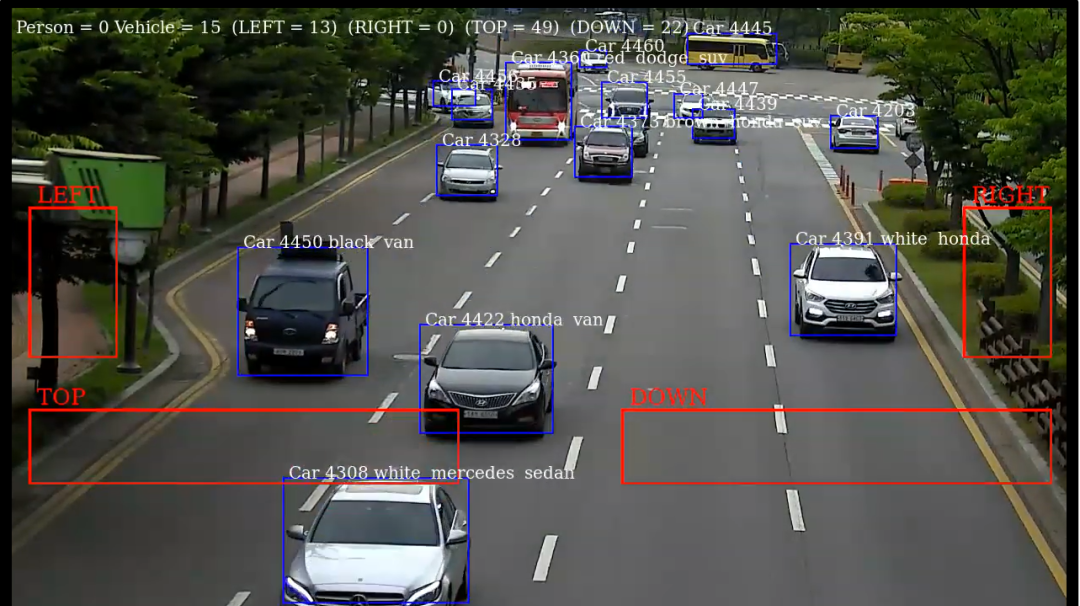
YOLOv3的发布已经过去了两年有余,但是由于其优秀的检测性能和灵活的部署方案,以及基本满足实时预测的能力,至今仍有许多相关领域工作者将其作为目标检测工程项目的主要算法,而安防就是主要应用场景之一。在智能安防中,车辆识别、人员识别、路径预测和跟踪、行为分析都是重中之重,而这些只需要我们对YOLOv3进行合理的修改和训练,就几乎可以全部实现。下面是YOLO的一些常见应用场景。